概念
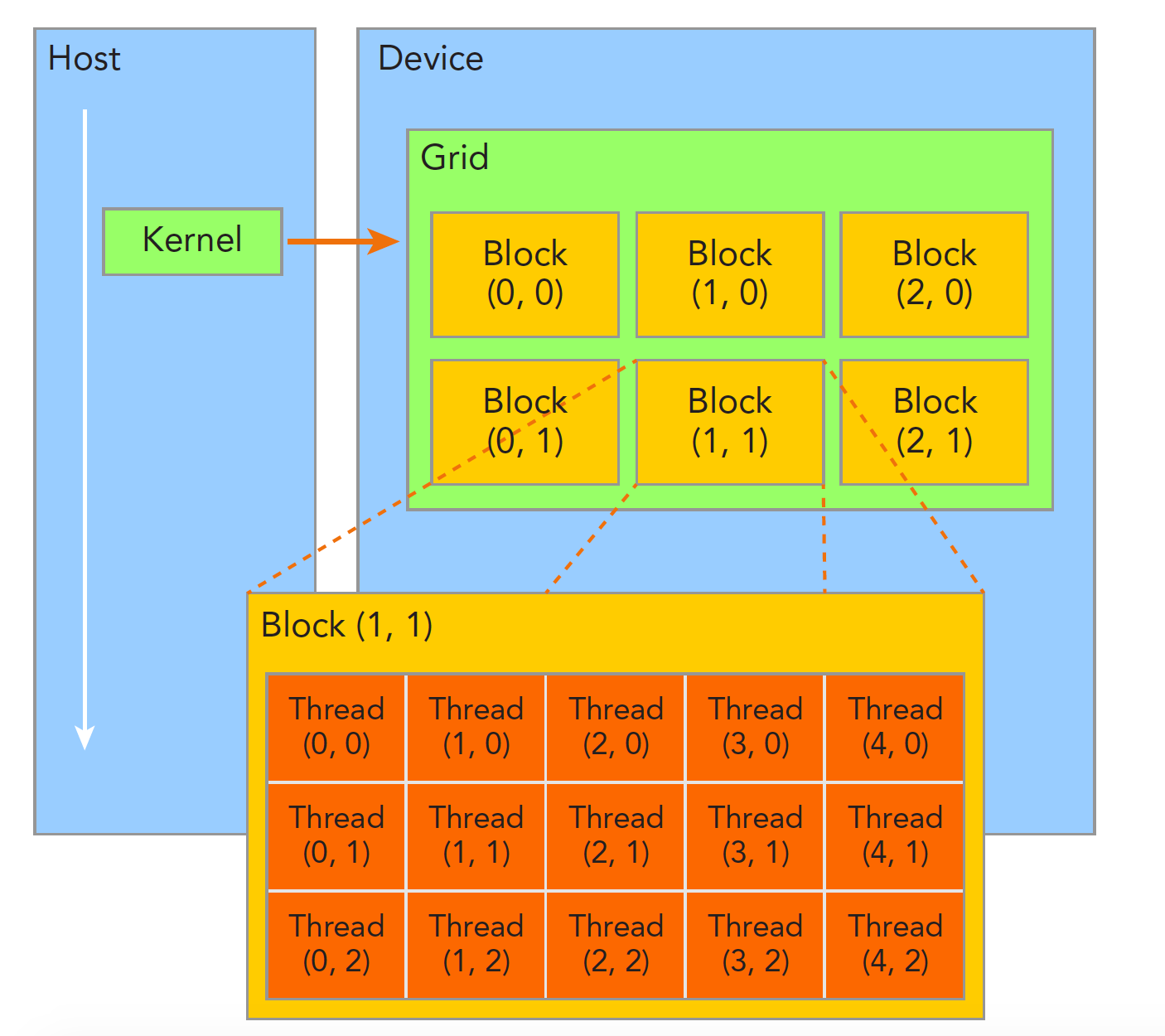
- grid:每一个核函数对应一个grid
- block:每一个grid内部包含若干block
- Thread:每一个block内部又包含若干Thread
(线程分块是逻辑上的划分,物理上线程不分块)
调用核函数时<<<grid_size, block_size>>>是对对线程块的配置(线程数量可以高于GPU上Core的数量)
block中最多允许1024个线程,grid中最多允许 $2^{31}-1$ 个block块
一维线程模型
- 每个线程在核函数中都有一个唯一的身份标识
- 每个线程的唯一标识由
<<<grid_size, block_size>>>确定,grid_size, block_size保存在内建变量(build-in variable)中。gridDim.x:该变量的数值等于执行配置中变量grid_size的值blockDim.x:该变量的数值等于执行配置中变量block_size的值
- 线程索引保存成内建变量:
- blockIdx.x:该变量指定一个线程在一个网格中的线程快索引值,范围为
0~gridDim.x-1 - threadIdx.x:该变量指定一个线程在一个线程快中的线程索引值,范围为
0~blockDim.x-1
- blockIdx.x:该变量指定一个线程在一个网格中的线程快索引值,范围为
推广到多维线程
- CUDA可以组织三维的grid和block
- blockIdx和threadIdx是类型为uint3的变量,该类型是一个结构体,具有x,y,z三个成员(3个成员都为无符号类型的成员构成):
- $\begin{cases}blockIdx.x\blockIdx.y\blockIdx.z\end{cases}$
- $\begin{cases}threadIdx.x\threadIdx.y\threadIdx.z\end{cases}$
- gridDim和blockDim是类型为dim3的变量,该类型是一个结构体,具有x,y,z三个成员
- $\begin{cases}blockDim.x\blockDim.y\blockDim.z\end{cases}$
- $\begin{cases}blockDim.x\blockDim.y\blockDim.z\end{cases}$
- 取值范围
- blockIdx.x范围:[0, gridDim.x-1]
- blockIdx.y范围:[0, gridDim.y-1]
- blockIdx.z范围:[0, gridDim.z-1]
- threadIdx.x范围:[0, threadIdx.x-1]
- threadIdx.y范围:[0, threadIdx.y-1]
- threadIdx.z范围:[0, threadIdx.z-1]
(内建变量仅在核函数内有效,且无需定义)
gridDim和blockDim没有指定的维度默认为1,例如
1 | hello<<<2, 4>>>(); |
这里:
$\begin{cases}blockDim.x = grid_size\blockDim.y = 1\blockDim.z = 1\end{cases}$
$\begin{cases}blockDim.x = block_size\blockDim.y = 1\blockDim.z = 1\end{cases}$
定义多维网格和线程块(C++构造函数语法):
1 | dim3 grid_size(Gx, Gy, Gz); |
注意:索引块的排序与平常的矩阵排序略有不同,按照图一所示的方式进行排序
注意:多维网格和多维线程块本质是一维的,GPU物理上不分块
对于二维线程模型,如图一所示,每个线程的唯一标识计算如下:
1 | int tid = threadIdx.y * blockDim.x + threadIdx.x; |
多维线程块中的线程索引与多维网格中的线程块索引:
1 | int tid = threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x; |
网格和线程块的限制条件
- 网格大小限制
- gridDim.x最大值———$2^{31}-1$
- gridDim.y最大值———$2^{16}-1$
- gridDim.z最大值———$2^{16}-1$
- 线程块大小限制
- blockDim.x最大值———1024
- blockDim.y最大值———1024
- blockDim.z最大值———64
(注意:线程块总的大小最大为1024!)