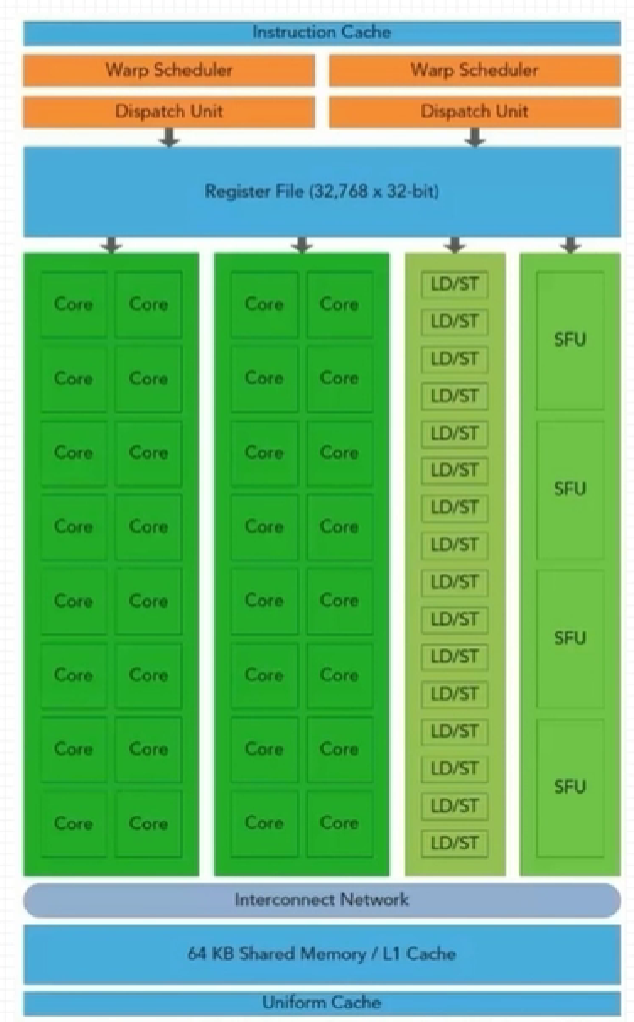
流多处理器–SM
- GPU并行性依靠流多处理器SM(Streaming multiprocessor)来完成
- 一个GPU是由多个SM构成的,Fermi架构SM关键资源如下:
- CUDA核心(CUDA Core)
- 共享内存/L1缓存(shared memory/L1 cache)
- 寄存器文件(RegisterFile)
- 加载和存储单元(Load/Store Units)
- 特殊函数单元(Special Function Unit)
- Warps调度(Warps Scheduler)
GPU中每个SM都可以支持数百个线程并发执行。
以线程块block为单位,向SM分配线程块,多个线程可被同时分配到一个可用的SM上。
当一个线程块被分配好SM后,就不可以再分配到其他SM上了。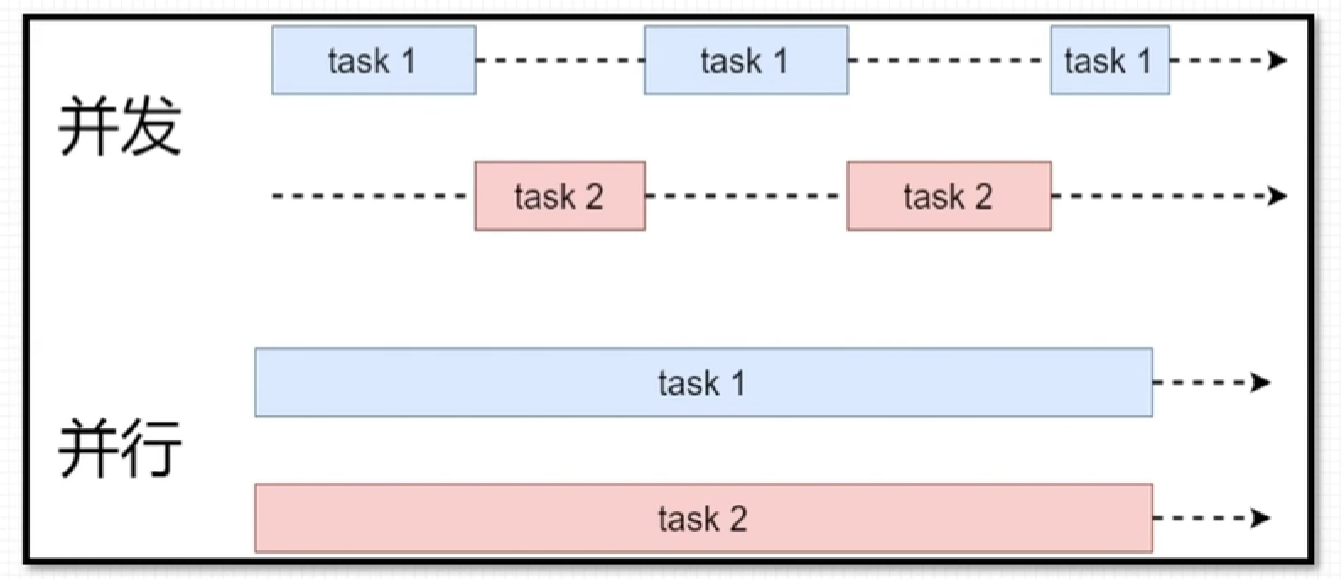
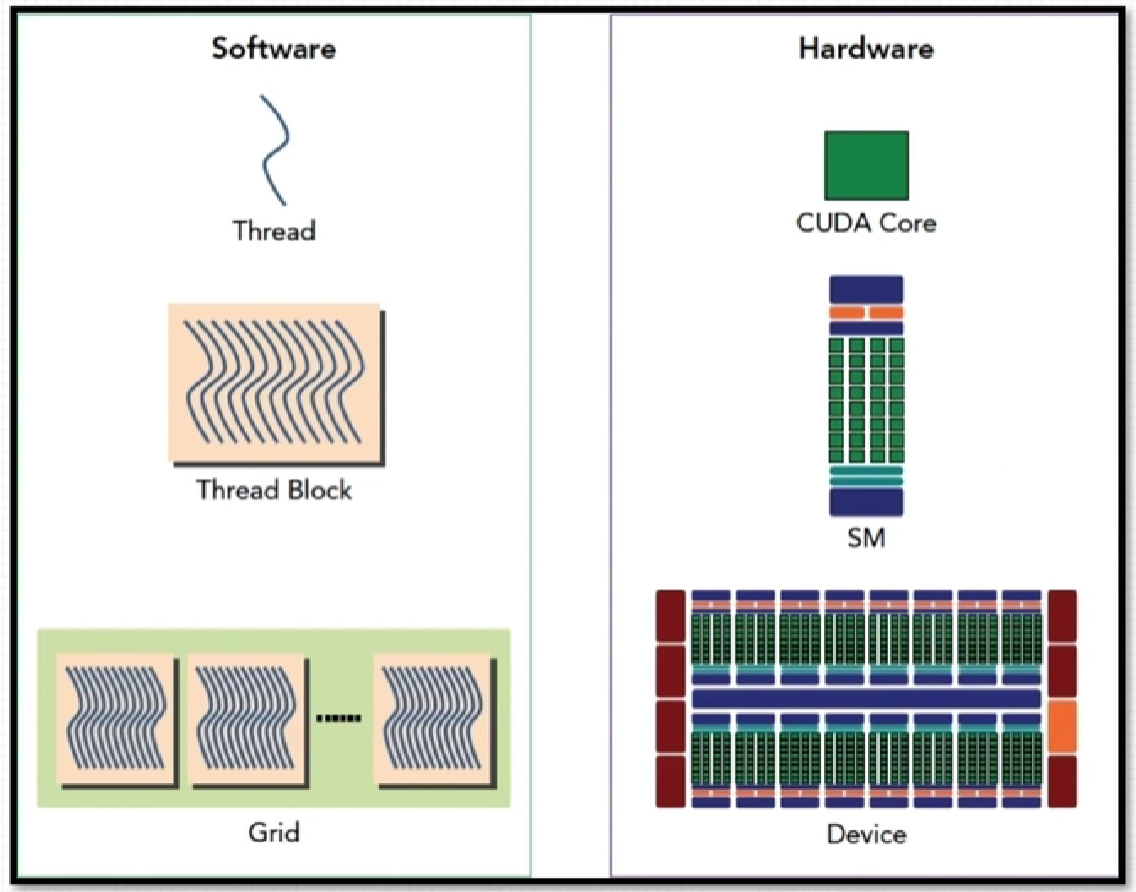
- 网格中的所有线程块需要分配到SM上进行执行
- 线程块内的所有线程分配到同一个SM中执行,但是每个SM上可以被分配多个线程块
- 线程块分配到SM中后,会以32个线程为一组进行分割,每个组成为一个wrap
线程束
CUDA采用单指令多线程SIMT架构管理执行线程,每32个为一组,构成一个线程束。同一个线程块中相邻的32个线程构成一个线程束。
具体的说,一个线程块中第0到第31个线程属于第0个线程束,第32个到第63个线程属于第1个线程束,以此类推。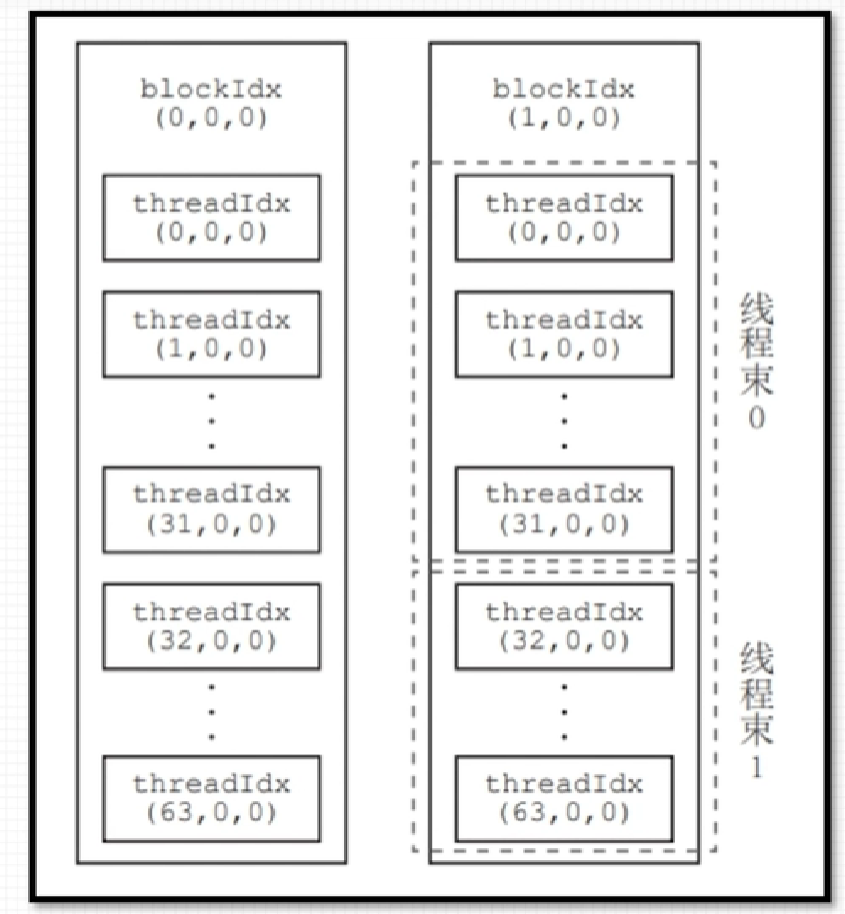
- 每个线程束中只能包含同一个线程块中的线程
- 每个线程束包含32个线程
- 线程束是GPU硬件上真正做到了并行
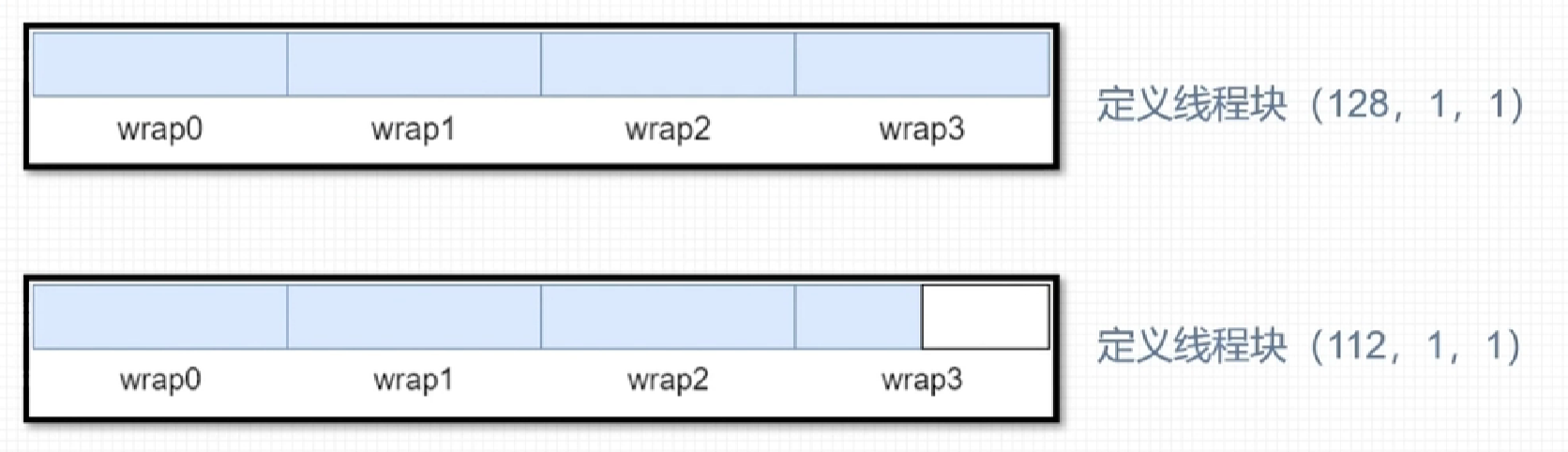
- 线程束数量=ceil(线程块中的线程数/32)