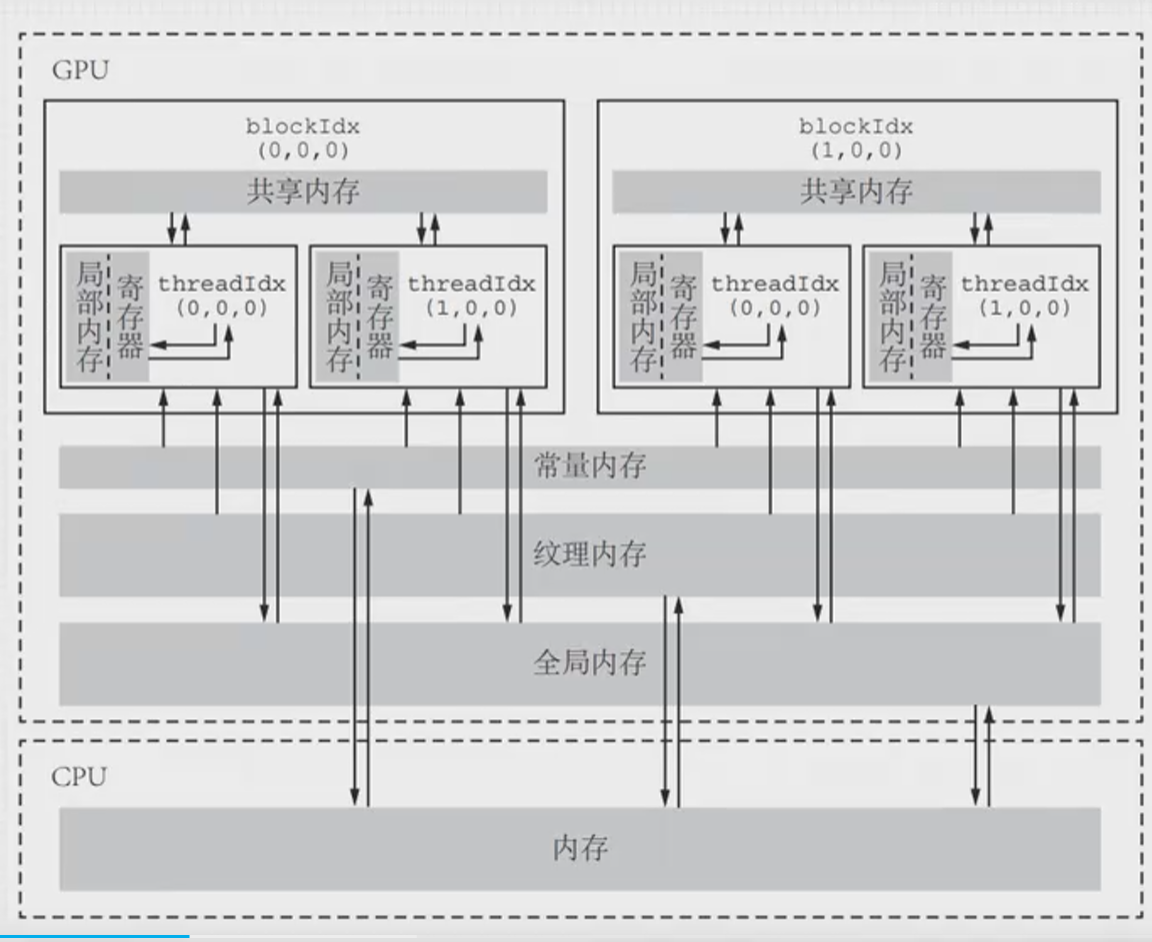
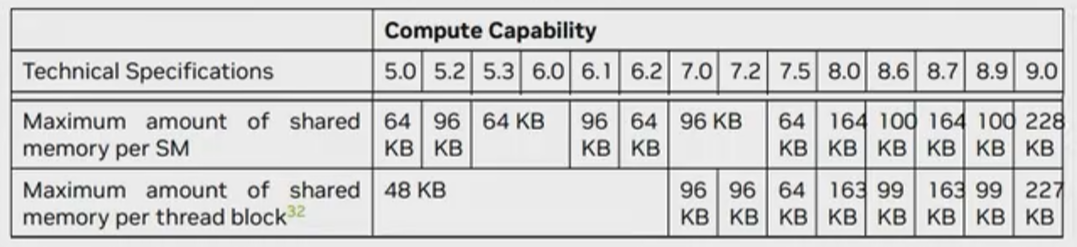
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| #include<iostream>
#include<cuda_runtime.h>
#include "common.cuh"
extern __shared__ float s_array[];
__global__ void Kernel_1(float *d_A, const int N){
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
if(n < N){
s_array[tid] = d_A[n];
}
__syncthreads();
if(tid == 0){
for(int i=0;i<32;i++){
printf("kernel_1: %f, blockIdx: %d\n", s_array[i], bid);
}
}
}
int main(int argc, char const *argv[])
{
int devID = 0;
cudaDeviceProp deviceProps;
CUDA_CHECK(cudaGetDeviceProperties(&deviceProps, devID));
std::cout << "运行GPU设备:" << deviceProps.name << std::endl;
int nElems = 64;
int nbytes = nElems * sizeof(float);
float* h_A = nullptr;
h_A = (float*)malloc(nbytes);
for(int i=0;i<nElems;i++){
h_A[i] = float(i);
}
float* d_A = nullptr;
CUDA_CHECK(cudaMalloc(&d_A, nbytes));
CUDA_CHECK(cudaMemcpy(d_A, h_A, nbytes, cudaMemcpyHostToDevice));
dim3 block(32);
dim3 grid(2);
Kernel_1<<<grid, block, 32>>>(d_A, nElems);
CUDA_CHECK(cudaFree(d_A));
free(h_A);
CUDA_CHECK(cudaDeviceReset());
return 0;
}
|