核心优势
O(1)推理复杂度:
单token推理时间恒定,总推理时间随序列长度线性增加,transformer平方增长
内存占用恒定,不随序列长度增加
推理时间和内存占用随模型尺寸线性增长
这意味着:大模型的硬件限制和部署成本将大幅降低,CPU以及非NV加速卡均可部署
服务器上部署大模型的成本将大幅降低,普通台式机和笔记本将能在本地部署大模型,手机端部署也成为可能
RNN和Transformer各自的局限性
RNN在训练长序列时容易出现梯度消失问题
RNN在训练过程中无法在时间维度上进行并行化,限制了其可扩展性
Transformer具有二次复杂度,长序列任务中计算成本高和占用内存多
文章贡献
提出了RWKC网络架构,结合了RNNs和Transformer的有点,同时缓解了它们已知的限制
提出了一种新的线性注意力机制
展示了RWKV在处理涉及大规模模型和长距离依赖关系的任务时的性能、效率和扩展能力
RWKV架构
含义
R:作为过去信息的接受程度的接受向量
W:位置权重衰减向量。可训练的模型参数
K:键向量,类似于传统注意力机制中的K
V:值向量,类似于传统注意力机制中的V像Transformer一样训练
RWKV高度并行化,提高了可扩展性
处理批大小为B,长度为T的序列的时间复杂度为O($BTd^{2}$)
计算$wk{v_t}$ 依靠串行扫描复杂度为O(BTd)
三种机制捕捉序列信息
RKWV通过三种机制(循环、时间衰减和token-shift)的组合来捕捉和传播序列信息:
循环:通过时间步传递局部信息和捕捉序列中的复杂关系
时间衰减:通过逐渐减小过去信息的影响,隐式地引入位置信息
token-shift:引入bi-gram,在当前输入和上一个输入之间线性插值,模型自然地聚合和控制输入通道中的信息
CPU高速运行RWKV
CPU上可以INT4/INT5/INT8告诉运行RWKV
INT8模式,速度快,精度损失小
可以直接编译出独立运行的exe,支持全平台,包括Linux Windows Mac ARM
总结
RWKV提出了几个关键改进和策略,使其能够捕捉局部性和长距离依赖关系,并通过以下方式解决了当前架构的局限性:
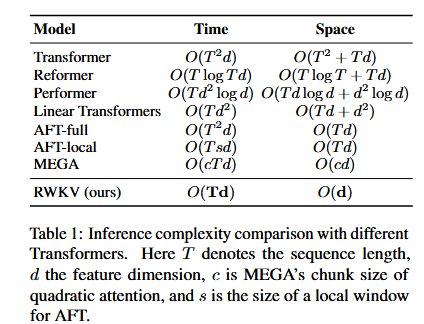
实现线性注意力的RNN,将计算复杂度从Transformer的$O({T^2}d)$ 降低为$O(Td)$
实现了高效的并行训练和高效的串行推理
提出了一些更好的训练初始化方法
限制
RWKV的线性注意力虽然带来了显著的效率提升,但也可能限制了模型在非常长的上下文中回忆细节的能力。相比标准Transformer的二次注意力所保持的全部信息,RWKV通过单个向量表示在时间步上进行信息传递。相对于传统的自注意力机制,模型的循环架构本身限制了其”回望“之前信息的能力。虽然时间衰减有助于防止信息丢失,但与完全的自注意力机制相比,它在机制上存在一定的限制。
与标准的Transformer模型相比,prompt engineering的重要性增加了。RWKV中的线性注意力机制限制了prompt的信息传递。因此,精心设计prompt可能对模型在任务上的表现更加关键。
未来工作
通过改进时间衰减公式和在保持效率的同时探索初始模型状态,提高模型表达能力
在$wk{v_t}$ 计算中应用并行扫描(parallel scan),将计算成本降低到$O(B\log (T)d)$ ,进一步提高RWKV的计算效率
研究将RWKV应用与encoder-decoder架构,是的RWKV可以应用与更丰富的场景,如seq2seq和多模态
利用RWKV的状态(或上下文)进行序列数据的可解释性、可预测性和安全性研究
把LoRA等参数高效的微调方法引入RWKV