CUDA全称(Compute Unified Device Architecture)统一计算架构。
巨量的矩阵运算、归一化、softmax运算等,并行计算多。
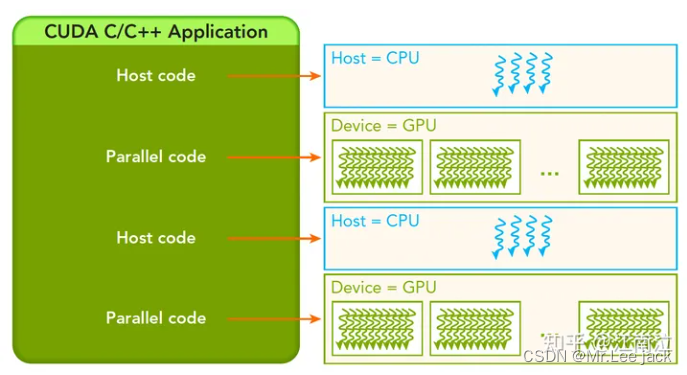
并行GPU,顺序CPU。
数据处理方式
佛林分类法(根据指令和数据进入CPU的方式对计算机架构进行分类,分为以下四类)
单指令单数据(SISD):传统的单核数据处理方式
单指令多数据(SIMD):单核执行一条指令完成多数据处理(游戏中向量、矩阵)
多指令单数据(MISD):多核执行不同的指令处理单个数据(少见)
多指令多数据(MIMD):多核执行不同的指令处理多个数据
为了提高并行计算的能力,架构上实现下面这些提升性能:降低延迟(latency):指操作从开始到结束所需要的时间,一般用微秒计算,延迟越低越好
增加带宽(bandwidth):单位时间内处理的数据量,一般用MB/s或者GB/s表示
增加吞吐(throughput):单位时间内成功处理的运算数量
共享内存的多处理器系统
包括单片多核,多片多核主要是针对同设备多核进行数据通讯,GPU是众核架构,表述为Single Instruction, Multiple Thread(SIMT),不同于SIMD,SIMT是真正的启动了多个线程,执行相同的指令,去完成数据的并行运算。
典型的CUDA程序处理流程
分配内存(Host和Device),数据初始化,将Host数据拷贝到Device。
调用Kernel函数处理数据,然后存在Device上。
讲数据从Device拷贝回Host。
内存释放。
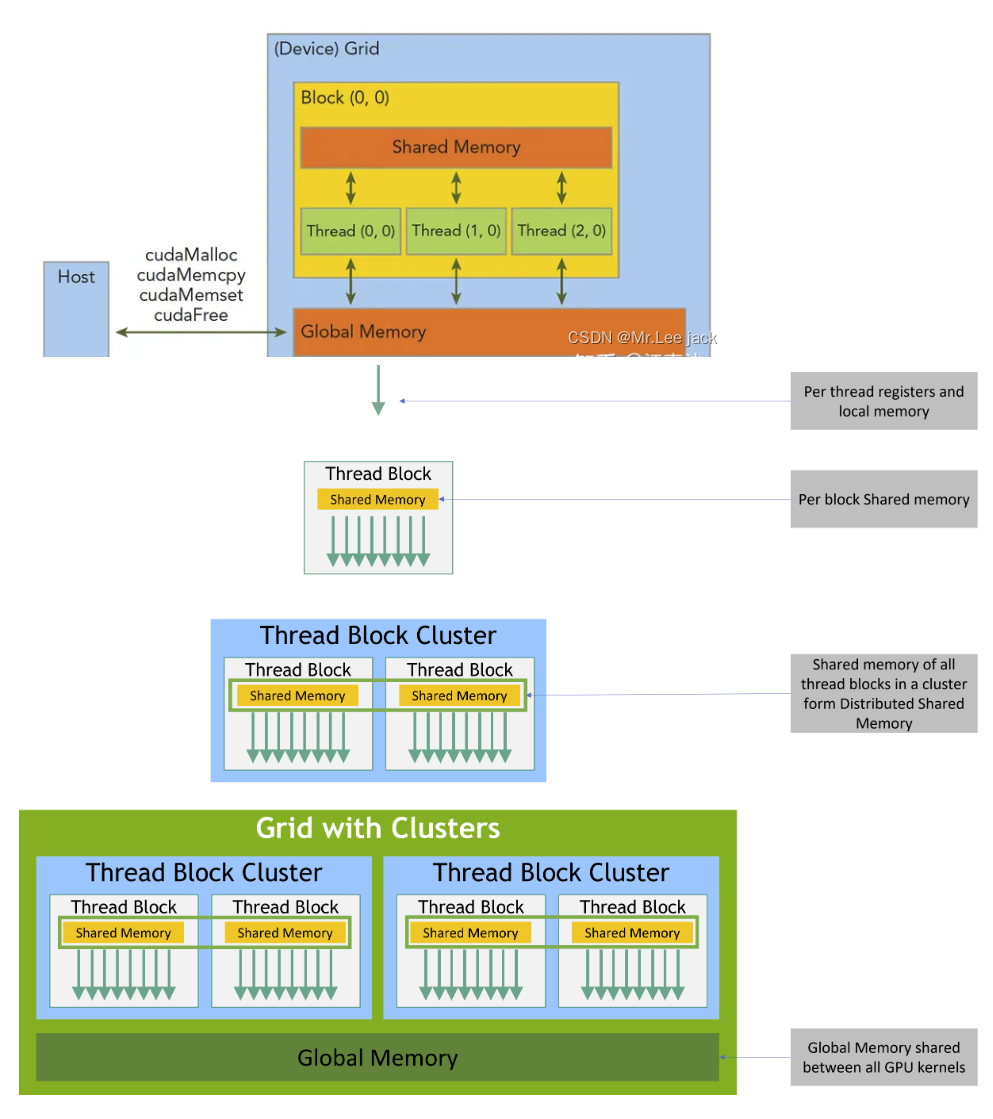
内存管理
| 标准C函数 | CUDA函数 | CUDA函数说明 |
|---|---|---|
| malloc | cudaMalloc | GPU分配内存 |
| memcpy | cudaMemcpy | 用于Host和Device之间的数据传输 |
| memset | cudaMemset | 设定数据填充到GPU内存中 |
| free | cudaFree | 释放GPU内存 |
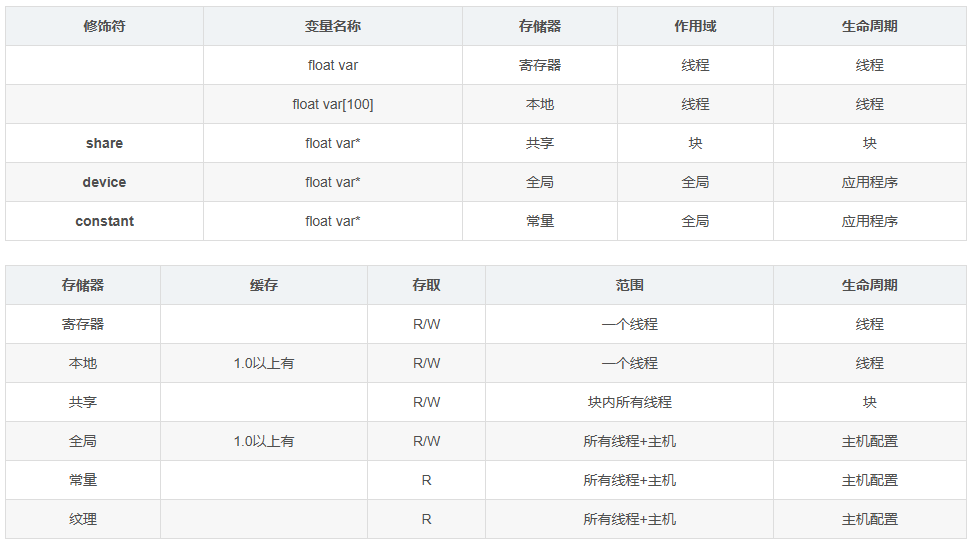
CUDA线程在执行期间可以访问多个内存空间的数据。
每个线程都有私有本地存储。
每个线程块都有对该块的所有线程可见的共享内存,并且与该块具有相同的生命周期。
线程块簇中的线程块可以对彼此的共享内存执行读、写和原子操作。所有线程都可以访问相同的全局内存。
还有两个可供所有线程访问的附加只读内存空间:常量内存空间和纹理内存空间。
一个Kernel所launch的所有线程称为grid,他们共享相同的全局内存空间(global memory space)
一个grid由多个block(线程块)组成,block内部的线程可以通过以下两点进行协作(不同block间的线程不能协作)
- block本地同步(synchronization)
- block本地共享内存(sharedmemory)
一个线程通过blockIdx(grid内的index)和threadIdx(block内的index)这两个坐标变量(三维类型unit3)来唯一标识(线程运行的时候这两个变量会被CUDA赋上相应的坐标值,可以直接使用)
grid和block的维度信息通过gridDim和blockDim(dim3)来表示
gridDim:表示一个grid里面有多少个blocks
blockDim:表示一个block里面有多少个threads
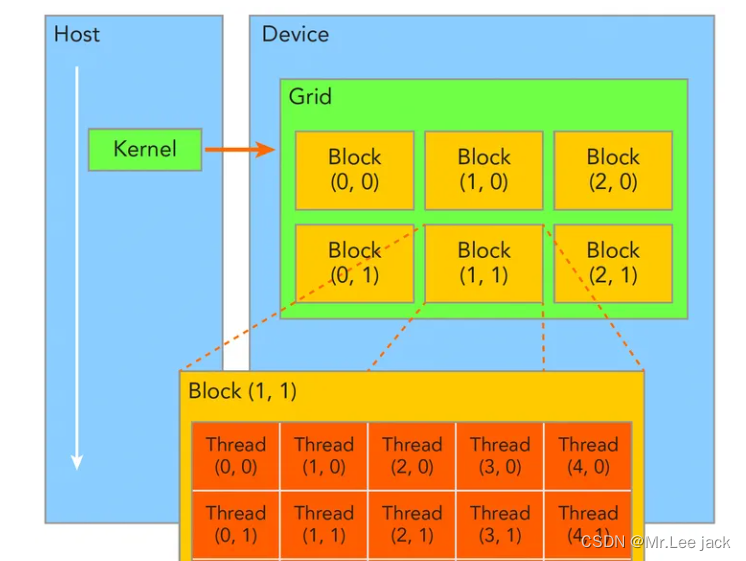
线程块结构
为了方便起见,threadIdx是一个3分量向量,因此可以使用一维、二维或三维线程索引 来标识线程,形成一维、二维或三维线程块,称为线程块。这提供了一种自然的方式来调用域中元素(例如向量、矩阵或体积)的计算。

每个块的线程数量是有限的,因为块中的所有线程都应驻留在同一个流式多处理器核心上,并且必须共享该核心的有限内存资源。在当前的 GPU 上,一个线程块最多可以包含 1024 个线程。
然而,一个内核可以由多个形状相同的线程块来执行,因此线程总数等于每个块的线程数乘以块数。
块被组织成一维、二维或三维线程块网格,如图4所示。网格中线程块的数量通常由正在处理的数据的大小决定,该数据通常超过系统中处理器的数量。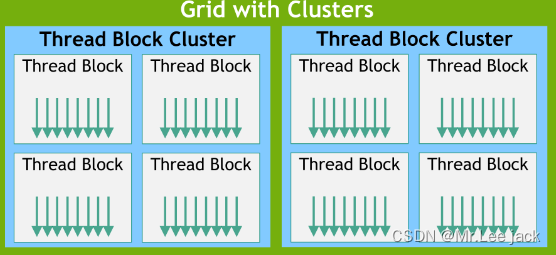
随着 NVIDIA计算能力 9.0的推出,CUDA 编程模型引入了一个可选的层次结构级别,称为由线程块组成的线程块集群。与如何保证线程块中的线程在流式多处理器上共同调度类似,集群中的线程块也保证在 GPU 中的 GPU 处理集群 (GPC) 上共同调度
GPU架构
GPU架构就是由可扩展的流式多处理器(Streaming Multiprocessors简称SM)阵列所构建,整个硬件的并行就是不断复制这种架构实现的。通常每个GPU都有多个SM,每个SM都支持上百个线程的并行,所以GPU可以支持上千个线程的并行
SM中的核心部件
CUDA Cores:核心,是最小的执行单元
Shared Memory/L1 Cache:共享内存和L1缓存,他们共用64KB空间,根据Bl
Register File:寄存器,根据线程划分
Load/Store Units:16个数据读写单元,支持16个线程一起从Cache/DRAM存取数据
Special Function Units:4个特殊函数处理单元,用于sin/cos这类指令计算
Warp Scheduler:Warp调度器,所谓Warp就是32个线程组成的线程束,是最小的调度单元
GPU内存
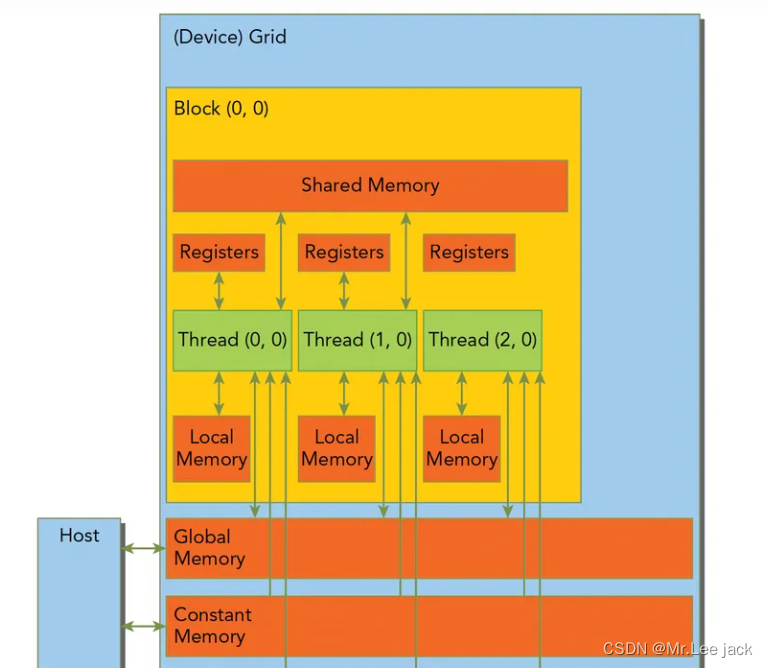
寄存器:GPU上访问最快的存储空间,是SM中的稀缺资源,对于每个线程是私有的,Fermi架构中每个线程最多63个,Kepler结构扩展到255个。如果变量太多寄存器不够,会发生寄存器溢出,此时本地内存会存储多出来的变量,这种情况对性能影响较大。
本地内存:本质上是和全局内存放在同一块存储区域中(compute capability 2.0以上的设备,会放在SM的一级缓存,或者设备的二级缓存上)具有高延迟、低带宽,编译器可能会将以下变量存放于本地内存:
- 编译时期无法确定索引引用的本地数组
- 可能会消耗大量寄存器的较大本地数组/结构体
- 任何不满足核函数寄存器限定条件的变量
共享内存:因为是片上内存,所以相比全局内存和本地内存,具有较高的带宽和较低的延迟
- SM中的一级缓存,和共享内存共享一个64k的片上内存,L1不可编程,共享内存可以
- 切勿过度使用共享内存,导致部分线程块无法被SM启动,影响Warp调度
- 可以使用__syncthreads()来实现Block内线程的同步
常量内存:驻留在设备内存中,每个SM都有专用的常量内存缓存
- 常量内存在核函数外,全局范围内声明,对于所有设备,只可以声明64k的常量内存
- 核函数无法修改,Host端使用cudaMemcpyToSymbol接口初始化
纹理内存:驻留在设备内存中,在每个SM的只读缓存中缓存,对于2D数据的访问性能较好
全局内存:GPU上最大的内存空间,延迟最高,使用最常见的内存,访问是对齐访问,也就是一次要读取指定大小(32,64,128)整数倍字节的内存,所以当线程束执行内存加载/存储时,需要满足的传输数量通常取决与以下两个因素:
一级缓存:每个SM都有一个一级缓存,与共享内存公用空间
二级缓存:所有SM公用一个二级缓存
只读常量缓存:每个SM有
只读纹理缓存:每个SM有