软件层面
- Thread:一个CUDA的并行程序会被许多个Thread来执行
- Block:一个block包含多个Thread,同一个block中的Thread可以同步,也可以通过shared memory通信
- Grid:多个block构成grid
warp
SM采用的SIMIT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
一个CUDA core可以执行一个thread,一个SM的CUDA core会分成几个warp(即CUDA core在SM中分组),由warp scheduler负责调度。尽管warp中的线程从同一程序地址,但可能具有不同的行为,比如分支结构,因为GPU规定warp中所有线程在同一周期执行相同的指令,warp发散会导致性能下降。一个SM同时并发的warp是有限的,因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和warp并发数量。
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是inactive状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。由于warp的大小一般为32,所以block所含的thread的大小一般要设置为32的倍数。
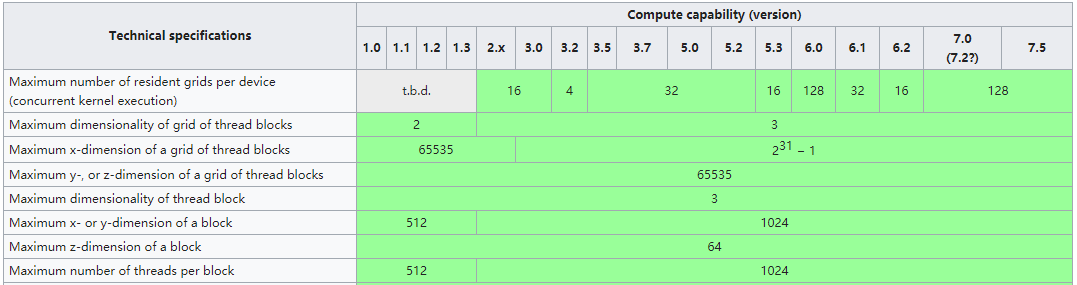
不同CUDA版本或在编译时没有指定架构的情况下,可能CUDA版本也会对thread,block,grid在不同维度的大小产生影响。